Blog / AI-SDLC
SoftwareForge | Technical Depth In AI-SDLC: Beyond Code Generation


Kumar Chivukula
Co-founder, CEO
TL;DR
Engineering velocity metrics mask structural decay, as coding agents generate code that compiles but violates undocumented system architectures, transforming development speed into a liability that compounds design debt.
Because AI assistants operate in isolation, without memory of prior sessions, they introduce silent systemic failures, such as transient dependency vulnerabilities and race conditions, that elude standard pull-request reviews.
Maintaining long-term system integrity requires transforming static documentation into living, queryable specifications, forcing agents to evaluate architectural boundaries and compliance rules before writing a single line.
Unrestricted code generation lacks a natural unit of control, necessitating a shift to machine-readable work orders that restrict the agentic blast radius and enforce explicit traceability from intent to deployment.
Evaluating AI platform maturity hinges not on generation throughput, but on the capacity to reverse-engineer legacy codebases, isolate architectural drift, and provide deterministic audit trails for security compliance.
What Technical Depth Means In AI-Assisted Software Delivery
Technical depth in AI-assisted software delivery is the ability to preserve and apply system knowledge throughout the software lifecycle. It ensures generated code aligns not only with a task, but also with architecture, security requirements, compliance rules, and operational constraints. Without technical depth, code may compile, pass tests, and satisfy ticket requirements while still conflicting with assumptions elsewhere in the system. As organizations adopt AI-assisted development, software quality increasingly depends on how well context, governance, and dependencies are maintained across delivery, not just on how quickly code is generated.
The challenge is not unique to AI-assisted development. Companies such as Netflix, Atlassian, and Meta have invested heavily in platform engineering, architectural governance, and developer tooling to manage technical debt at scale. As systems grow, preserving architectural knowledge becomes as important as writing new code. AI-assisted development magnifies the same problem when context, intent, and governance are not carried forward during implementation.
The data behind those anecdotes is now substantial. Forrester's 2025 Technology Predictions found that 75% of technology decision-makers expect their technical debt to reach moderate-to-severe levels by 2026, driven directly by AI-accelerated development practices. Gartner went further, projecting that over 40% of agentic AI projects will be canceled before reaching production by end of 2027, not because the tools failed, but because of escalating costs, unclear business value, and governance gaps that nobody built guardrails around.
On the client side, enterprises already spend 40 to 50% of their engineering budgets maintaining legacy systems whose original intent is blurred, context is gone, and governance trail doesn't exist. Layer AI on top of that, and another 40% of the AI budget disappears into coordination, rework, and drift, what amounts to an "AI tax" the traditional SDLC was never designed to absorb.
This article covers three things: why code generation speed is the wrong bottleneck to chase, where technical depth breaks down in agent-based delivery across real codebases, and how software factory workflows rebuild the context layer that stateless AI sessions discard by design.
The Limits Of Code Generation Speed
A coding agent reads a prompt, reads surrounding files, and writes an implementation without much friction. Stripe deployed Claude Code across 1,370 engineers and one team migrated 10,000 lines of Scala to Java in four days, work scoped at 10 engineer-weeks. But throughput at generation time says nothing about whether the resulting system is correct at the level that matters for a payments platform, a healthcare record system, or anything with a compliance officer attached.
An agent can write a JWT issuance flow that compiles cleanly, passes its own test suite, and issues a valid admin token to anyone who sends a well-formed request, because nothing in its context told it that credential verification was non-negotiable.
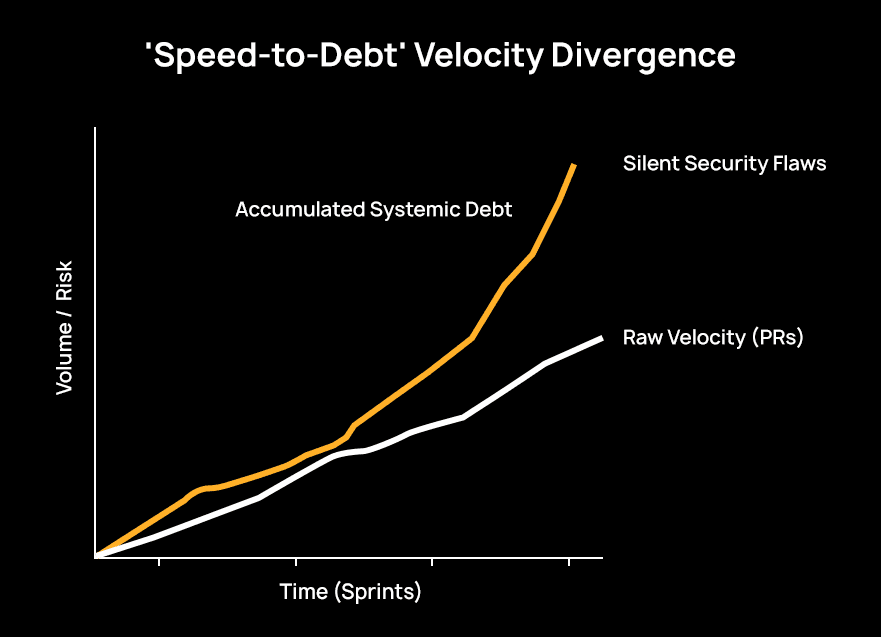
Speed multiplies problems of this kind rather than surfacing them. When one engineer writes one service over two weeks, a design flaw shows up in code review or a design doc. When six agents implement six tickets across eight services in the same sprint, each working from a prompt and a slice of the repository, the same class of flaw shows up six times, in six places, none of which talk to each other.
None of this shows up in a demo, a 30-second clip of an agent scaffolding a CRUD API looks identical whether or not the API has an underlying authorization model. The difference only becomes visible three sprints later, when a query against the live cluster finds a service account with cluster-wide access to secrets.
Architectural Context Loss In Stateless AI Workflows
Most AI coding sessions are stateless by design; each session reads whatever files it needs for the current task, makes its changes, and ends. The next session starts with no memory of what came before. It doesn't know what yesterday's session decided, why, or what else in the system now depends on that decision.
Multiply that across a system with eight services and six concurrent tickets, and you get this: an agent implementing a Buy-Now-Pay-Later integration in paymentservice pulls in bnpl-sdk-java. That SDK transitively pulls in payment-commons, which pulls in spring-security-oauth2-resource-server:6.2.3, four levels deep in the dependency tree. That version carries CVE-2024-38821, a CVSS 9.8 JWT bypass. The agent had no way to know this chain existed. It pulled a legitimate SDK and moved on; run the audit yourself and you'll see why it wasn't caught sooner. There's no single command covering a monorepo with independently managed services:
cd services/paymentservice |
The output for payment service alone runs 340 lines. The vulnerable package appears on line 287 of that output. Finding it means cross-referencing every line against a CVE database, by hand, across eight separate trees. Meanwhile, Trivy had flagged the same CVE in a container scan. Dependabot had already opened a PR for it, eleven days earlier, unmerged because nobody could confirm it wouldn't break the BNPL integration. Three systems had sighted the same finding, none of them connected to each other or to the agent that introduced the code.

This is what fragmented tooling looks like at agent throughput: not each tool failing, each tool doing exactly what it was designed to do, producing noise that a human has to manually deduplicate after the fact.
How Engineering Teams Define Technical Depth
When engineering leaders evaluate AI-assisted delivery platforms, technical depth is ultimately a question of how much system understanding exists between business intent and generated code. Most AI coding tools focus on generation. SoftwareForge approaches the problem differently by building a software factory that continuously maintains context across requirements, architecture, governance, and implementation.
In practice, technical depth on SoftwareForge means every generated artifact can be traced back to its originating business objective, architectural decision, compliance requirement, and operational constraint. The platform is designed to answer questions that become critical at enterprise scale: Why was this code generated? Which requirement authorized it? Does it conform to the approved architecture? What security controls apply to it? Can the implementation be audited months later?
This is why SoftwareForge measures maturity beyond code output. The objective is not simply to generate working software faster, but to preserve the technical reasoning that allows large systems to remain maintainable, compliant, and understandable as hundreds of agent-assisted changes accumulate over time.

Code volume and model sophistication don't move any of these needles. Traceability, architecture fidelity, security requirements baked in at generation time, operational constraints, and governance, that's the real checklist, whether the team is shipping a new microservice or untangling a fifteen-year-old Java monolith.
Where Technical Depth Breaks Down In Agent-Based Development
The three layers above break down in specific, observable ways once agents work in parallel across a real codebase. Each has a name, a mechanism, and a failure signature.
Context Rot Across Long-Lived Engineering Projects
Context rot occurs when the information an agent needs to make a correct decision still exists somewhere but not in a form that is reachable at generation time. The knowledge isn't gone. It's scattered across a Maven dependency tree, a Trivy scan that ran in a different pipeline, and a Dependabot PR sitting unmerged for eleven days, and no single one of those sources has the full picture.
As repositories grow, the fragmentation gets worse, not better. More services means more independent dependency graphs with no shared visibility between them. More history means more architectural decisions made under different assumptions, some still valid, some quietly outdated. An agent generating code today can produce something that's locally correct, it compiles, it passes its unit tests, it satisfies the ticket, while being globally inconsistent with a constraint that exists three services away and that nobody told it about.
Architectural Drift Created By Independent Agent Actions
Architectural drift is what happens when multiple agents, working on different tickets in the same sprint, each make a locally reasonable decision that collectively pulls the system away from its intended shape.
A concrete case: a flash-sale pricing engine landed in catalog and a new checkout flow landed in cartservice, in parallel worktrees. Both services touched the same inventory locking logic. Neither agent had visibility into what the other was doing. The result was a race condition in which the flash-sale pricing logic could bypass the inventory lock that the checkout flow depended on. It didn't surface in either test suite, because each tested its own change in isolation. It appeared on day 35, in a load test, after both branches had been on main for weeks.
Code review catches this late almost by construction. The conflict only exists at the intersection of two PRs that were reviewed separately, possibly by different reviewers, possibly days apart.
Security And Compliance Gaps Introduced By Partial Context
An architecture analysis of an order-processing system surfaced five problems in a single pass, all of them predictable outputs of generation without organizational context.
The login endpoint issued valid JWTs for any userId and role in the request body, with no credential check, because the agent implementing the JWT flow had no identity pattern in its context and built a fully functional token issuance flow with nothing behind it. Role-based access control middleware was correctly written and never wired into the order routes, meaning a customer token had identical access to an admin token on every order endpoint. GET /orders returned every user's order history to any authenticated caller, a textbook insecure direct object reference, because the agent optimized for "returns orders successfully" without awareness of the multi-tenancy boundary the system was supposed to enforce. A rate limiter's per-IP counter map grew without bound, no TTL decay, heading toward an OOM crash in any long-running process. And the error handler serialized raw internal messages, including upstream payment failures, directly into HTTP responses.
None of these five problems showed up in a CI build failure. None of them were caught by a linter either. The IDOR is the sharpest example: the existing test suite passed completely, because the tests verified that orders were returned, not that the returned orders belonged to the requesting user. The code did exactly what its tests checked for. The tests just weren't checking for what mattered.
The throughline: the defect doesn't originate in the implementation step. It originates in the gap between what the agent's context contained and what the system required, and implementation just makes that gap concrete.
Building Technical Depth Into Software Factory Workflows
SoftwareForge builds technical depth through its software factory model by maintaining a continuous chain between business intent, specifications, architecture, governance controls, work orders, and deployed code. Rather than treating AI generation as an isolated activity, the platform ensures every stage of delivery operates against the same shared source of context. This allows teams to scale agent-assisted development without losing the architectural understanding and governance controls that enterprise systems depend on.
Software factories don't create technical depth by generating more code. They create it by preserving requirements, architecture, governance rules, and operational constraints as software moves from planning to deployment. This section examines the workflows that keep AI-generated outputs connected to the system's intended design instead of producing isolated artifacts.
Converting Requirements Into Living Specifications
A living specification is a requirements document that's also a machine-readable contract. It's generated from intent, structured enough that an agent can query it during generation, and the same document a human reviews, approves, and amends, not a separate artifact that drifts away from what the team built.
A Forge-generated PRD for a modernization project includes explicit targets (Java 8/Spring 4 to Java 21/Spring Boot 3, JSP/jQuery to React, Oracle/MyBatis to Postgres/JPA, AI-ready REST and event APIs), non-functional requirements as numbers (remediate 14 high and 3 critical CVEs, raise test coverage from 22% to 80%, OAuth 2.1 with scoped tokens, 7-year audit trail mapped to SOC 2 CC7.2), and an explicit out-of-scope section (no net-new features outside the modernization scope, regional data residency deferred). The out-of-scope section does as much work as the targets: it's the difference between an agent that stays in its lane and one that helpfully starts refactoring adjacent code because nothing told it not to.
Traceability comes from the fact that every downstream work order points back to a line item in the spec. When someone asks why this service enforces a 15-minute token TTL, the answer is a line in a document that's still the current source of truth, because agents are building against it now, not against a kickoff snapshot.
Maintaining Persistent Context Across The Delivery Lifecycle
Persistent context means the architecture, the policies, and the requirements are reachable by every workflow stage, planning, implementation, testing, deployment, without each stage rebuilding its own partial picture from scratch.
Concretely, SoftwareForge exposes this as a workspace that any agent can query at any point in the pipeline: forge://workspace, which holds the parsed intent, the current ForgeScore, the PRD, the architecture, and the active work orders, all addressable and up to date. When a coding agent picks up a work order to implement charges.go, it starts from a record that already knows the service is in PCI-DSS scope, that PAN data can't be stored, that the database is Postgres via JPA, and that the build pipeline will reject anything introducing a CVE above medium.
For security and compliance workflows specifically, that context has to reflect live repository state, not a cached index. An index that's an hour stale during a compliance audit might miss a dependency added that morning or still believe authentication middleware exists after someone removed it. Governance decisions made against a version of the system that no longer exists are the mechanism by which audit gaps accumulate faster than anyone tracks.
Using Controlled Execution Models Instead Of Unrestricted Generation
A work order is the unit that turns "an agent with full repository access and a vague mandate" into "an agent authorized to make a specific, scoped, auditable change." Each work order is tied to a line item in the living spec, has an explicit scope, and feeds into the build pipeline before promotion.

The comparison with free-form generation isn't that controlled execution is slower. It's that free-form generation has no natural unit of approval. If an agent can read and modify anything in the repository in pursuit of a loosely specified goal, the only review point is the final diff, by which time the agent may have touched twelve files to accomplish what the ticket asked for in two. A work order constrains the blast radius before generation starts.
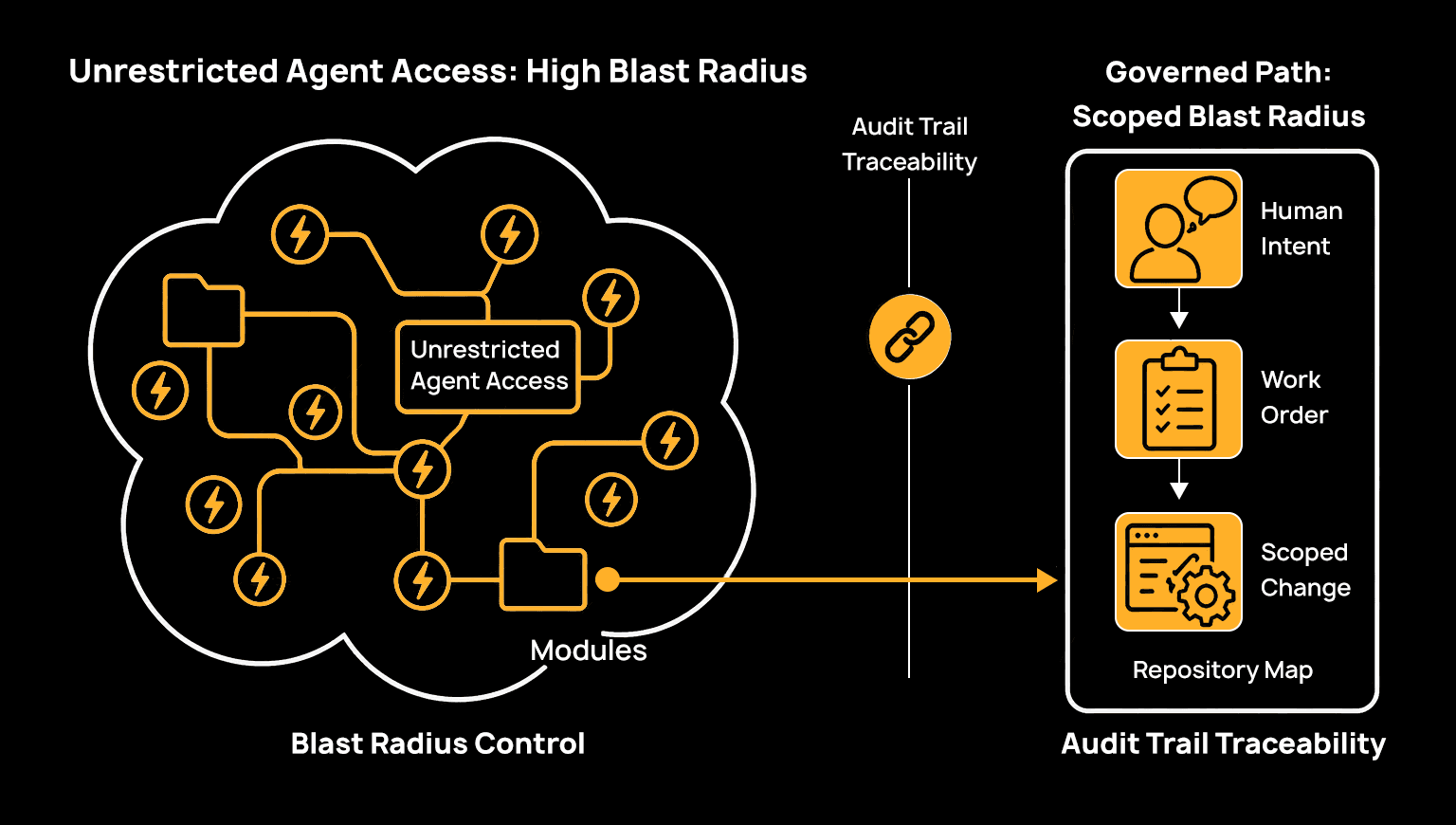
SoftwareForge authorizes all agentic actions through human-auditable work orders, making it structurally impossible to ship code that hasn't been through a governed path. The audit trail exists because every action traces back to a work order, every work order traces back to a spec line item, and every spec line item traces back to the original intent. As IDC Research Manager Katie Norton put it: "Forge is designed to bring architecture analysis, security scanning, compliance checks, and remediation into a coordinated workflow that supports more autonomous execution while preserving auditability and governance across the software lifecycle."
Evaluating Technical Depth In AI-SDLC Platforms
Platforms differ most in the things that don't come up during a demo. Here's what to look for after the sales call ends.
Questions To Ask Beyond Code Generation Capabilities
The demo question and the production question are not the same question. "Can it generate a working API endpoint from a prompt" is the demo question. Every serious tool on the market answers yes to that one. The production questions look more like: when the platform generates code, what context informed that generation, and can you inspect it? If the architecture changes next quarter, does previously generated code get flagged for review against the new architecture, or does it sit there, correct against an architecture that no longer exists? And if an auditor asks for the chain from a specific line of production code back to the business requirement that justified it, how many systems does someone have to open to answer that?
Demo quality hides delivery complexity because a demo is, by construction, a greenfield scenario with no history and no accumulated policy set to enforce. The hard part of AI-SDLC isn't generating the first version of something. It's generating the four hundredth change to something that already exists, in a way that's consistent with the three hundred and ninety-nine changes before it.
Signals That A Platform Understands System Context
A few capabilities distinguish a context-aware platform from a code assistant that requires a longer prompt. Specification generation that produces a structured, queryable artifact, not just a markdown summary, means the PRD/BRD/FRD output is something a downstream agent can parse for constraints, not just something a human reads once. Architecture analysis that classifies issues by remediation type, architectural versus implementation-level, matters operationally: "the rate limiter map has no TTL" has a clear fix path, while "the system has no real identity layer" requires a design decision before any of the dependent fixes make sense. And policy enforcement that operates inline, during generation and at merge time, rather than as a post-fact scan report that someone has to manually connect back to the triggering code.
Indicators Of Long-Term Maintainability
Two years from now, the question isn't "did the platform generate good code in 2026." It's "can we still explain why the system looks the way it does, and can we still change it safely."
Audit trails and decision traceability are the most direct indicators: can you reconstruct, for any piece of production code, the work order that produced it and the architectural decision it implements? Compliance mapping that survives policy changes matters more than compliance mapping that's accurate on day one, because every framework gets updated, scope changes, and a platform that mapped code to controls once at generation time has no mechanism for re-evaluating that mapping when the controls change. And modernization readiness is worth checking even if you're not modernizing anything right now: a platform that can reverse-engineer intent and architecture from an existing codebase is one that understands context can degrade and needs to be recoverable. That's the same capability you'll need when the engineers who wrote the original specs have moved on and the living spec is the only thing standing between "we know why this works this way" and "nobody knows, don't touch it."
The Convergence of Velocity and Veracity
The structural flaw in early AI-driven development is the prioritization of syntax over systems. While autonomous tools excel at converting isolated prompts into working code, typing speed was never the true engineering bottleneck. The actual constraint is systemic cohesion: ensuring every modification preserves architectural geometry, enforces security boundaries, and satisfies compliance mandates. When agents operate in stateless execution windows, they lack the historical context needed to prevent decay, turning raw generation speed into a mechanism that accelerates and distributes architectural debt across decoupled repositories faster than human review can intercept it.
Software Forge addresses this challenge by embedding technical depth directly into the software factory lifecycle. Intent is transformed into structured specifications, specifications become architecture-aware work orders, and every agent action executes within governed boundaries tied to compliance, security, and operational requirements. Because context remains persistent across the AI-SDLC, generated code is evaluated against the system it belongs to rather than against an isolated prompt. The result is an environment where delivery speed increases without sacrificing traceability, architectural integrity, or governance.
FAQs
1. What Does Technical Depth Mean In An AI-SDLC Environment?
Generated code stays traceable to the requirement that justified it, consistent with the system's architecture, and compliant with security and governance policy at the point of generation, not as a downstream check.
2. Why Is Technical Depth More Important Than Code Generation Speed?
Speed without depth means design and security flaws get replicated across services faster than anyone can review them. Veracode found that AI-generated code introduces security flaws in 45% of cases, and that rate doesn't improve as models get larger or faster.
3. How Does Context Engineering Contribute To Technical Depth?
It keeps architecture, policies, and requirements queryable by every agent at generation time. Decisions made in one service remain visible to agents working on dependent services, rather than each session starting from a partial, stale view of the system.
4. How Can Software Factories Preserve Technical Depth Across Large Projects?
By treating specifications as living, machine-readable documents rather than static files, maintaining a persistent workspace that reflects the current architecture rather than a snapshot, and routing every agent action through scoped, auditable work orders tied back to that spec.
On this page

Ship from spec to prod — governed.
AI speed without the drift. Forge carries your intent from idea to production in hours.
More from our blog
More articles

Ship enterprise software at AI speed.
Products
Build New Product
Modernize legacy code
Comparison
Company
About Us
Careers
Legal
Privacy Policy
© 2026 Forge. All Rights Reserved.